Gaucho: our evaluation tool

We talked recently about the importance of evaluation in continously improving and keeping Connie AI honest. At the beginning, we were running our evaluations through command-line scripts. We would check the output files into git, and as part of the commit we would diff the results and visually check that things were working well.
This worked for a while, until our evaluations grew long and it started to be too much effort to look at every single output. It also didn't offer us a good overview of the performance of the pipeline.

In July, I was in Buenos Aires for a few days escaping the New York summer. As I'm walking in front of the Casa Rosada, with this problem on my mind, Matt calls me and our quick catch-up becomes a good hour brainstorming this idea for a tool to help us move faster and more confidently with pipeline changes. Hence Gaucho.
With minimal code modifications, Gaucho allows us to execute evaluation runs and automatically create pipeline charts with aggregated stats.
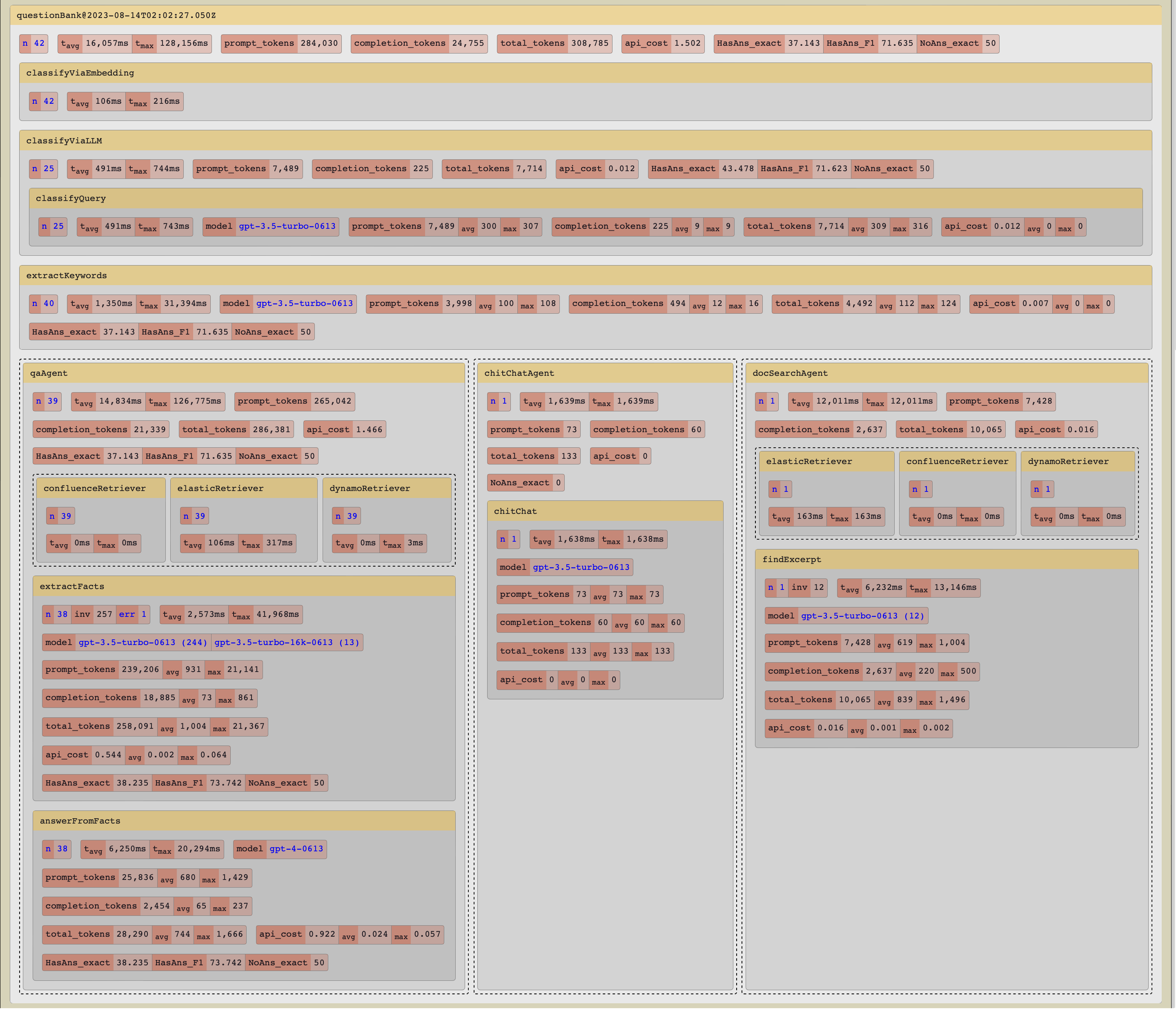
We can also drill into the details for each individual step in the pipeline and inspect the input arguments and output results for each item that ran through the pipeline.

Gaucho also allows us to compare between runs to see what has changed. For example, it shows us that our use of GPT-4 instead of GPT-3.5 in the final output step of the pipeline improves the quality of our answers, but it also nearly triples our overall costs and increases overall average latency by 20%. We can selectively test the effects of such replacements in different parts of the pipeline, and make more informed decisions.

In order to test isolated changes in the pipeline, we can pin down parts of it so that the inputs and outputs remain consistent across runs. For example, we can pin down the output of the retrieval tasks to ensure that the input to downstream steps is consistent even if our Confluence test site has been updated between two runs. This is particularly useful for LLM-based steps, where costs can run up quickly for large evals and output is not deterministic.
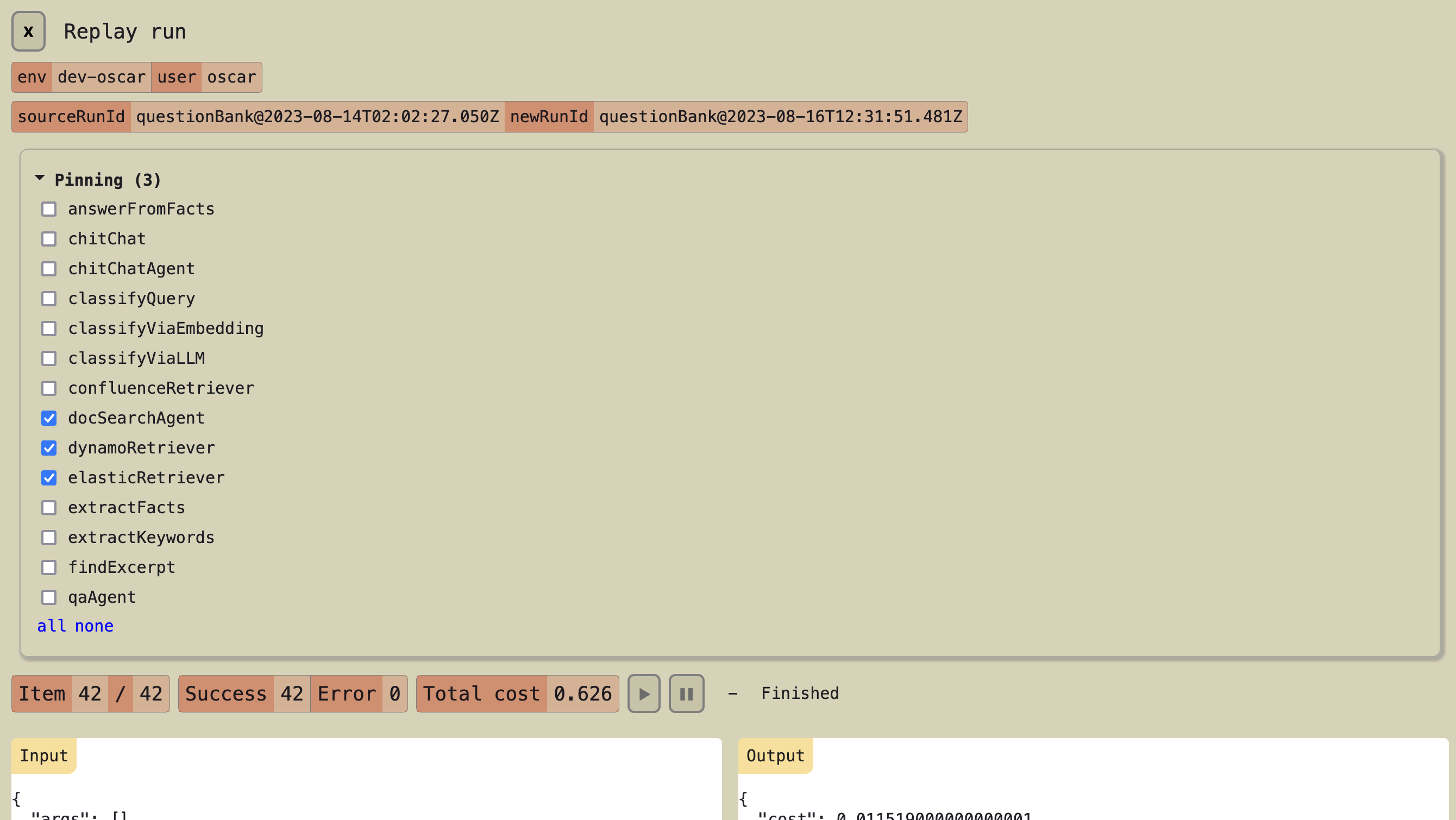
We believe that investing in solid tooling for evaluation is well worth it, as it allows us to try a lot more things and make faster progress, while being fully informed of the cost, latency and quality tradeoffs. As more and more LLMs become available we can move faster and more confidently when replacing or upgrading any of our pipeline steps with the technology we find to work best.