Evaluating Atlassian Intelligence

Back in April at their annual TEAM conference, Atlassian announced Atlassian Intelligence, a suite of AI-enabled features across the entire product line. This vision and level of commitment to AI's role in the future of every Atlassian product is very exciting. After a few months of eager anticipation, Atlassian opened the beta of Atlassian Intelligence to the general public on October the 2nd.
This seemed like a great opportunity to use our internal evaluation tool, Gaucho, to see how the initial release of Smart Answers for Confluence (which is part of Atlassian Intelligence) compares with our own Connie AI.
I need to preface this report by saying that it is not meant as a dis of Atlassian Intelligence or a thinly-veiled pitch for our product. Atlassian Intelligence only just launched in public beta after all. We are sure Atlassian is as committed to improving Atlassian Intelligence just as we are on improving Connie AI. Additionally, this is our own eval set and is biased towards use cases and features we've thought about and invested in. Even with those caveats, I think the results are useful and even enlightening about the challenges of building a quality RAG product.
We subjected Smart Answers to the evaluation set that we run for every release build of Connie AI. It is currently comprised of 66 questions over our internal test Confluence sites, with a variety of challenges including questions that require multi-document comparison, reasoning, table lookups and arithmetic operations.
This loosely means it got the correct answer 41% of the time, and some of the details right, but not all, an additional 12% of the time. For comparison, Connie AI scores 0.92 in F1 and 0.88 in exact, but see the caveats above. More information about evaluation scores can be found in this article.
In the rest of the article, we analyze some of the failure modes we've identified in this early version of Smart Answers in Confluence Search (Atlassian Intelligence).
Hallucination
We spent a lot of our early days figuring out ways to provide only factual information contained in your Confluence site, and know that it is not an easy task. Still, we were surprised by the extent to which Smart Answers hallucinates. Out of 66 questions in our eval set, we identified major hallucination in 6 answers (9%), and detail hallucination in 3 more (4.5%).
For example, it hallucinated the name of our company (Q: "What does ALU stand for?" A: "ALU stands for Atlassian Intelligence assistant.") even if our test site has a line saying verbatim "Here at ALU (Applied Language Understanding Inc.) we reward the wins and learn from the losses."
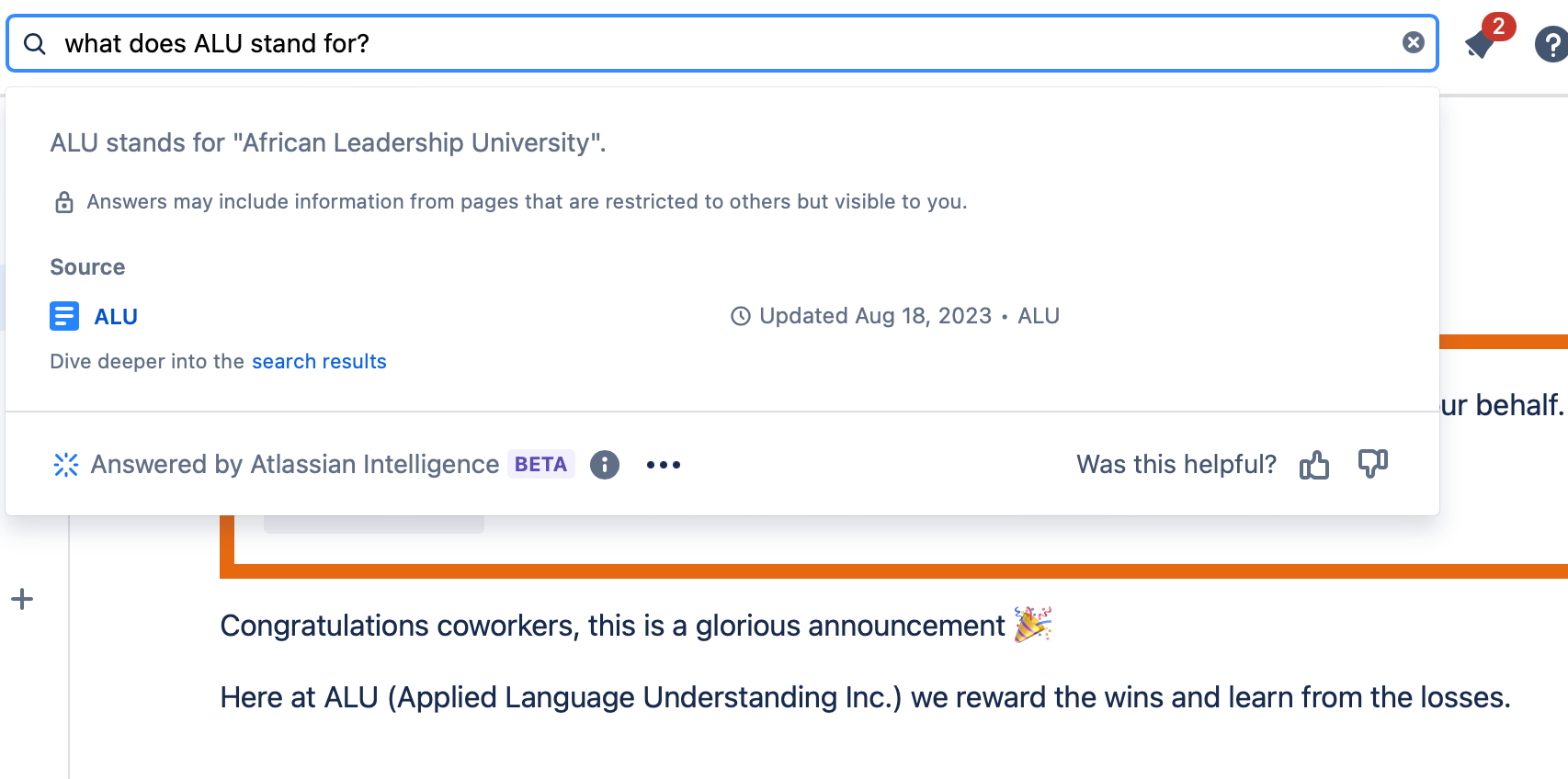
When hallucination happens, we noticed a tendency to make Atlassian part of the answer. We wonder if there's something in one of their prompts that causes the LLM to center in their company name. An alternative explanation could be that, since many of our test documents mention Atlassian, it's possible that in the final generation step they mangle the information from multiple documents or chunks without providing adequate context to the LLM.
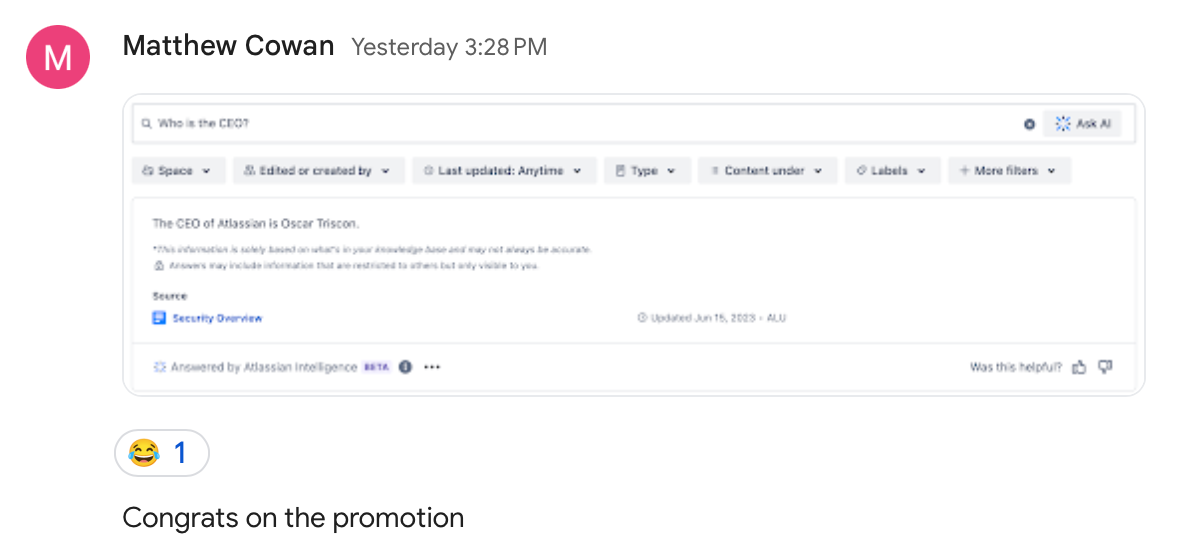
In any case, they don't seem to have managed to keep the LLM to the data included in the sites. It's easy to get Atlassian Intelligence to answer questions with general knowledge from the training set:
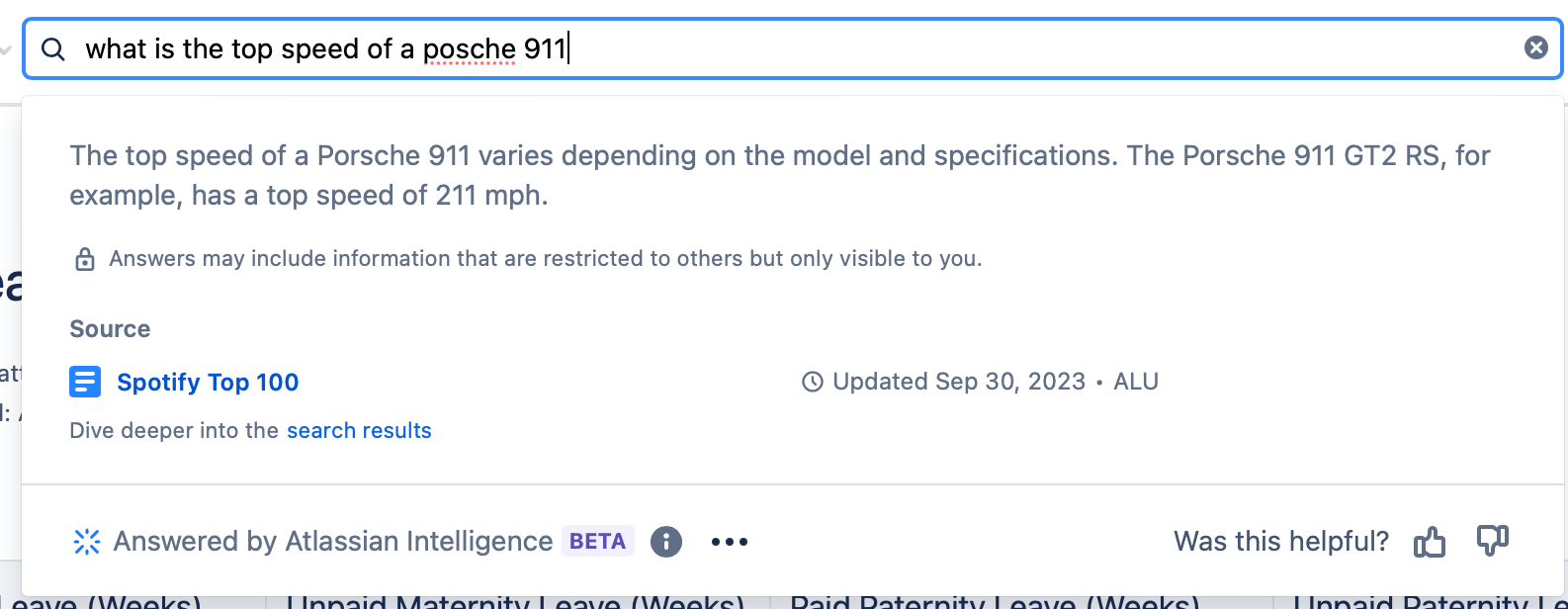
Particularly troublesome is the fact that hallucinated answers cite (incorrect) sources.
Retrieval failures
In 7 cases (10.6%), Smart Answers replied "Atlassian Intelligence doesn't have enough data to provide a response right now." when there was clearly data in the site to directly answer the question.
We reckon most of these are due to retrieval failure, i.e. the right chunk was not retrieved or ranked high enough to be considered in the generation phase, or not enough context was provided to the LLM.
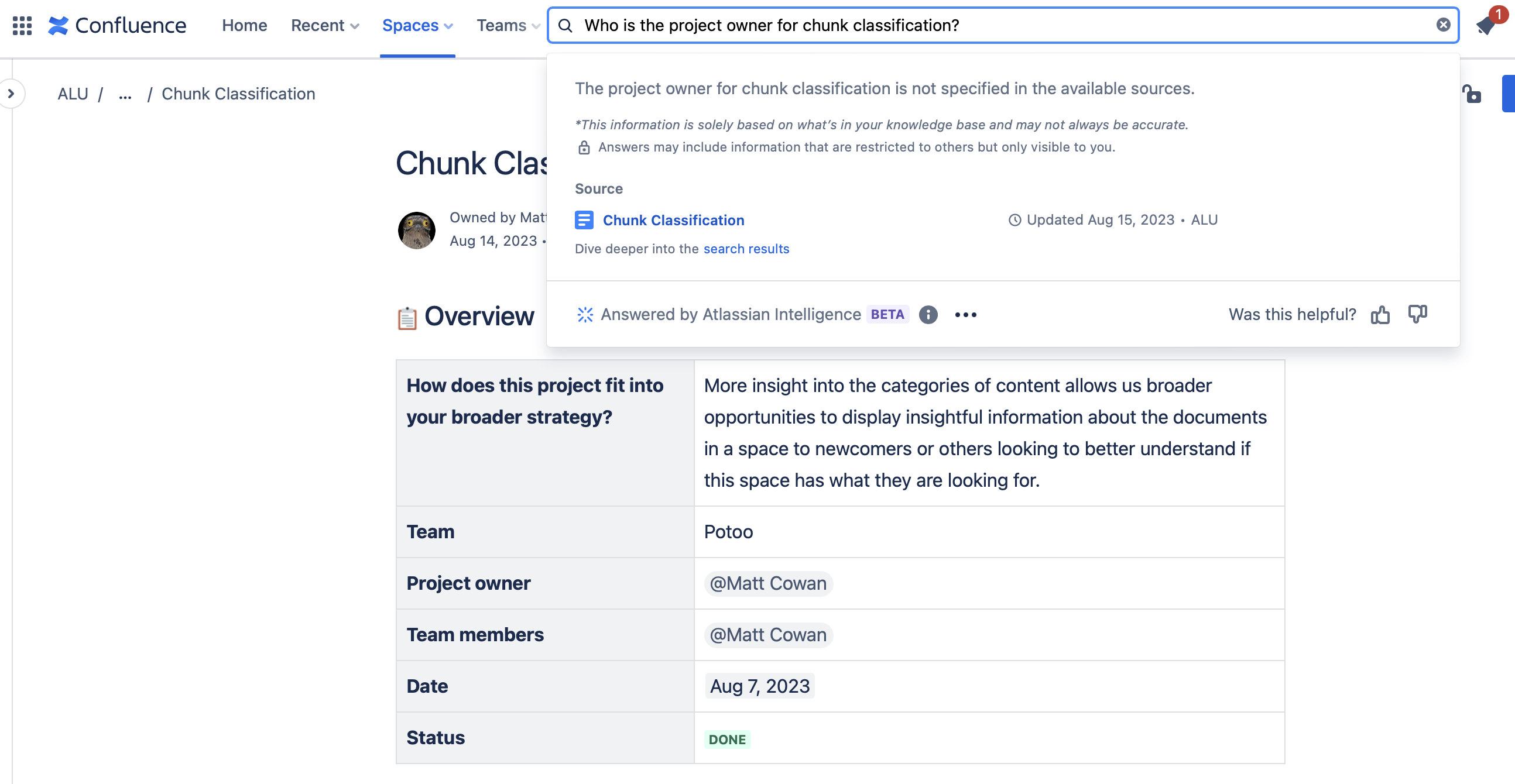
How chunking is performed is important for recall. In the screenshot above, you can see how not including the title of the document in what's sent to the LLM would fail to associate the content of the row "Project owner" with the project name in the document title.
Reasoning and multiple-fact comparison
In the simplest implementation, RAG is a two-step process of retrieval and presenting the LLM with the retrieved chunks and the question. If done carefully and with enough context, LLMs will do a generally great job of extracting the right answer.
Things get more complicated when the answer is not directly in the chunks presented but can be derived from them. Here, the failure mode we've noticed more commonly is lack of completeness: the LLM will consider some of the facts but not others, or even hallucinate seemingly-feasible data, and output an answer that seems correct until you realize that it's completely wrong in practice.
We have several test setups for this more complex scenario. One is a document with a table with the Spotify Top 100 songs at some point in time, along with statistics for each song. When presented with questions such as "What are the top 3 highest tempo songs on Spotify's top 100?", Smart Answers produced a semi-hallucinated list of songs and tempos that don't actually correspond to the ground truth. We got similar results in questions such as "How many artists have at least one song on the Spotify Top 100?", in which it will output a reasonable but incorrect number.
A second test setup contains a table of countries along with their GDP and population. While Smart Answers was able to calculate correctly the GDP per capita for a single country ("What is the GDP per capita of France?"), it failed when multiple countries were involved:
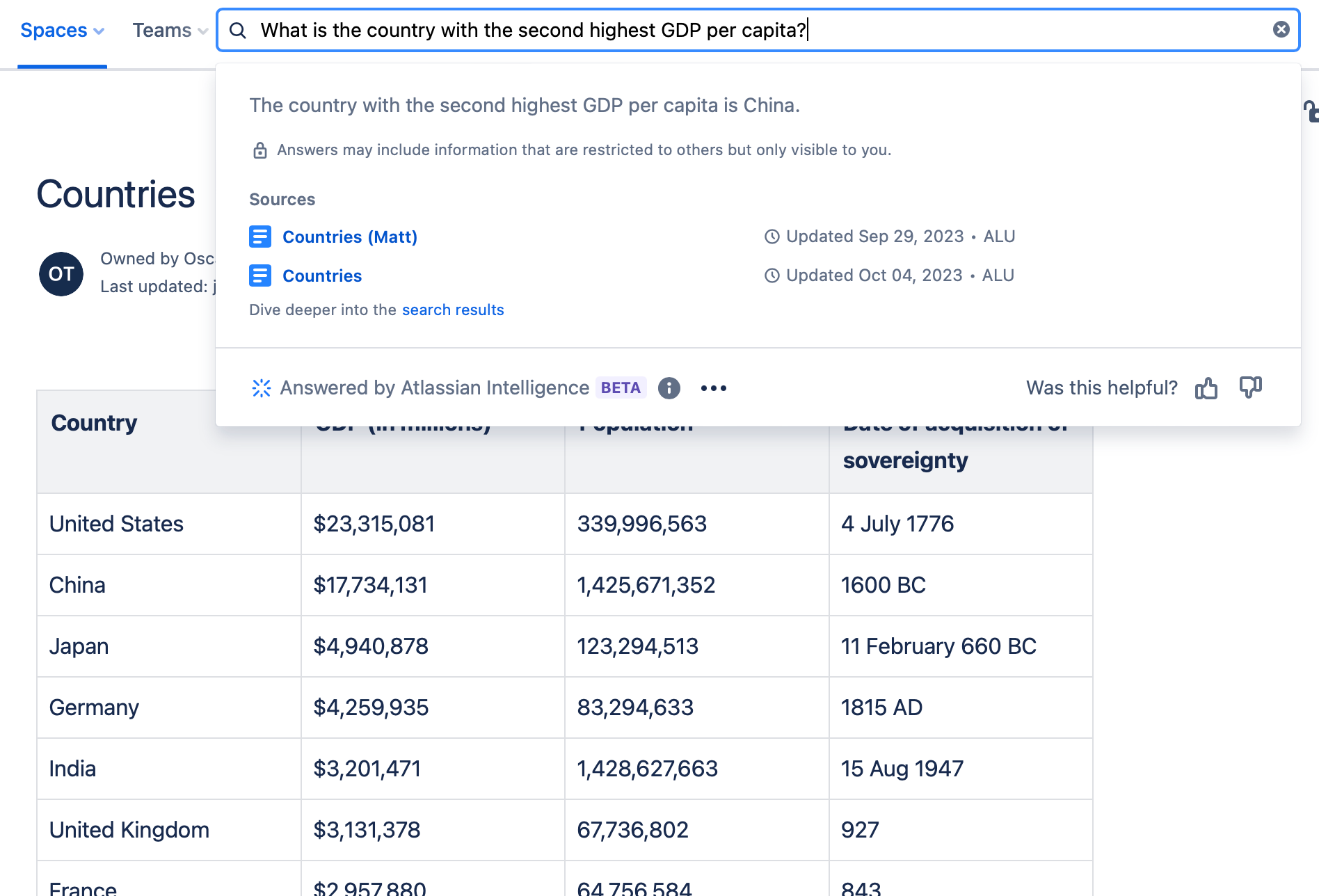
You may think we're being harsh here and trying to get Smart Answers to do things that are too hard. We believe that in order for AI to gain acceptance as a business tool, it has to provide answers that can be relied upon. Answering this type of question is far from intractable (see Tables and structured data, Introducing X-ray.)
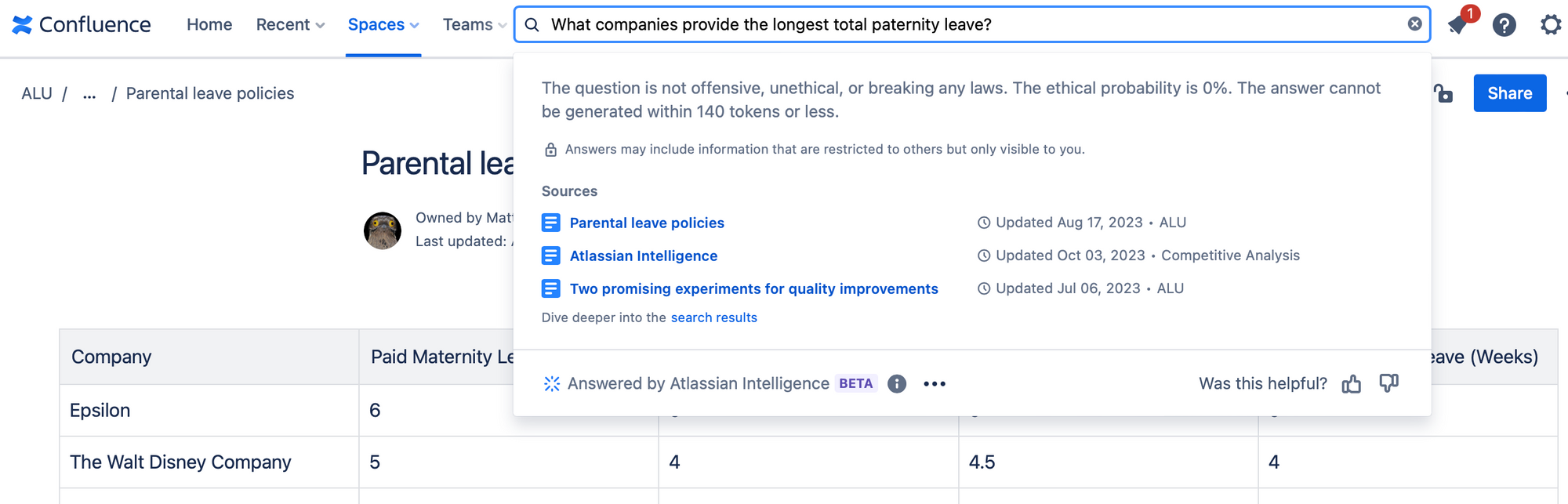
Finally, yet another similar test setup is a table of parental policies for different companies. With this document, Smart Answers failed to completely answer any questions and while we can only speculate as to the reason, we got some hints of the internal workings of Atlassian Intelligence's question answering pipeline:
Stale results
This was not part of the evaluation per se, but it's something we realized while capturing screenshots for this article.
Atlassian Intelligence heavily caches already asked questions, and doesn't mark the results as stale if a document is updated, or at least it takes quite a while to do so.
The result is that one can easily get stale answers:
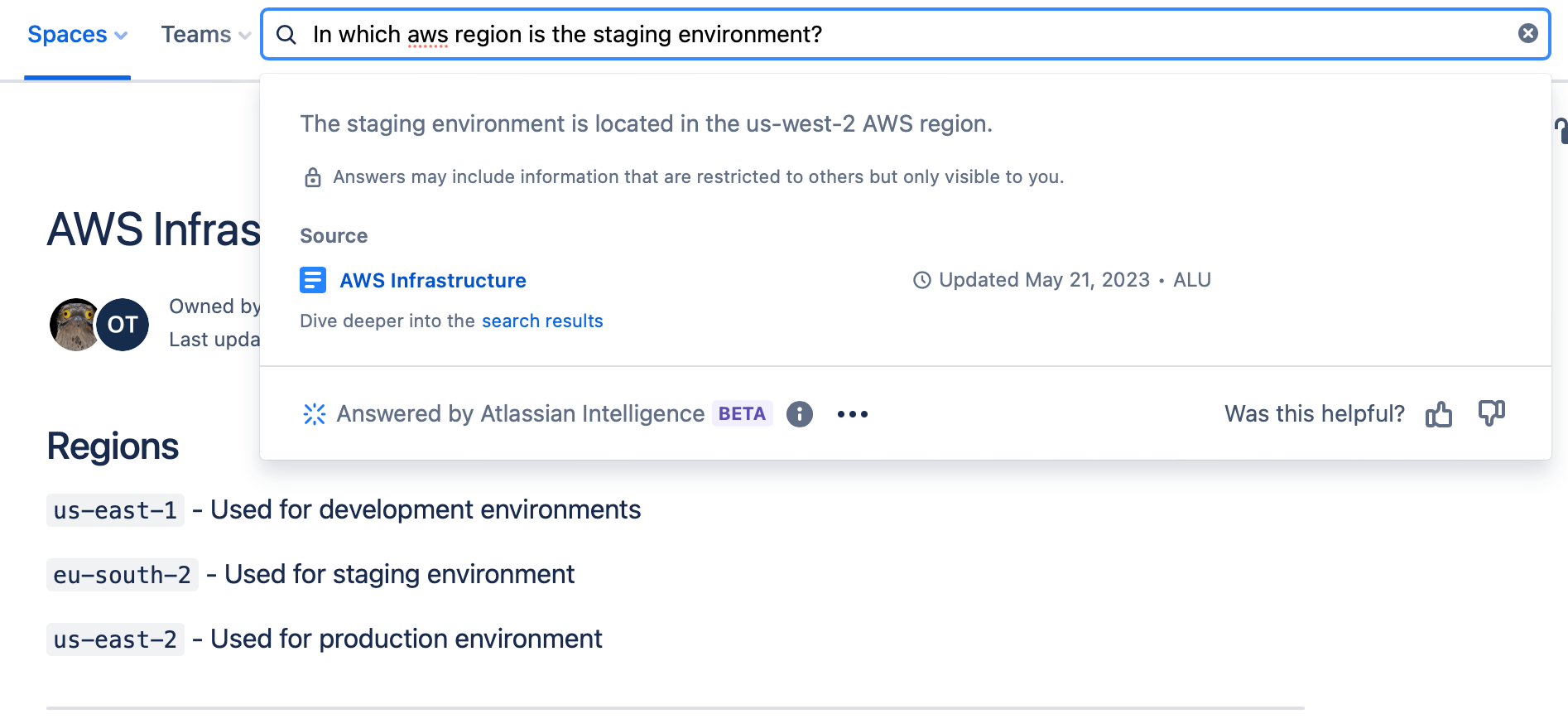
Given the often-authoritative tone of answers, we believe that information freshness is crucial for an AI to be relied upon.
Closing thoughts
As an industry, we are at the beginning of a marathon where we need to earn the public's trust in AI. We must realize that if you can't trust its output and need to validate it yourself, then AI question answering is strictly worse than the search it is trying to replace. (Coincidentally, a recent article in Wired makes precisely this case.)
Quality evaluation is an important tool to make sure we produce results that don't erode the public's perception of AI's value. But in addition to working hard to improve the reliability and correctness of our AI answers, we must invest in user-visible validation.
If you'd like to read on how we're building trustworthy AI, please head on to our post on Introducing X-ray.
As always, you can reach us at contact@alu.ai if you have thoughts or questions.